Designing a Zero-Dependency Webhook Fan-Out System in Go
Introduction
A webhook is an event driven endpoint that receives a request when some event gets triggered at the other end.
Let’s say you’re using a third-party email service to send emails from your app. Once you’ve sent an email, you might need to check if the email was read by the recipient but that’s the service provider’s job. They keep track of these events and will send the event to your app through a webhook.
Most of the time you can only register one webhook for a service. That means when using a third party app that might send webhook request (GitHub, stripe etc.), you can only set up one endpoint to receive it. However, there might arise situations when you need to propagate the event through multiple endpoints.
waford solves this problem by providing a mechanism to fan out distribute a webhook payload to multiple registered endpoints.
wafordis an asynchronous, highly concurrent system that guarantees “at-least-once” delivery without overwhelming downstream services.
Building waford
You receive a payload on the /ingress endpoint and you need to send it as a POST request to multiple registered endpoints(fan-out). Sounds simple right? Yeah well that’s what I thought too. A simple 1-2 hour max application did not only take 4+ hours and several refactors but also uses several incredible systems concepts to make sure it’s reliable and performant.
Initially, I wrote a simple /ingress endpoint that accepts the payload and wraps it with a Job struct.
type Job struct {
EventID string `json:"event_id"`
Payload json.RawMessage `json:"payload"`
RetryCount int `json:"retry_count"`
}My idea was to run a background worker that took these Job(s) and simple sent them to each configured destinations.
//get the current job from the buffer
current <- s.JM.JobBuffer
// send the payload to all destination
for dest := range Destinations {
err := sendRequest(current.EventID, current.Payload)
}The Partial Failure Problem
Now you might notice one real weakness of this design. Sure, it does exactly what it wants us to do and does it straightforward too. Take a payload, distribute it to all the necessary endpoints. That’s what we want right? Yeah, but we need to consider failures as well. The distribution might fail and in this case I’d have a problem of partial failures i.e. out of 5 configured destinations 2 might fail and we end up with a success rate of 3/5 and that is not acceptable.
Of course, since I’m running workers, I also had to provide a retry mechanism. It’s absolutely necessary. Based on my previous fan-out design, I now needed to keep track of which destinations per payload failed so that I could retry them—because there’s no point in retrying successful endpoints XD.
Now if you think about it, it gets a bit frustrating
Since we use the Job struct:
- You can use an array[] to store failed destination
- You can use an array[] to store all destination and remove successful ones as we go
- You can use hashmap to track these things and on and on and on…
No matter what data structure you use, this adds unnecessary complications to the system and our main goal as good engineers is to avoid unnecessary complications.
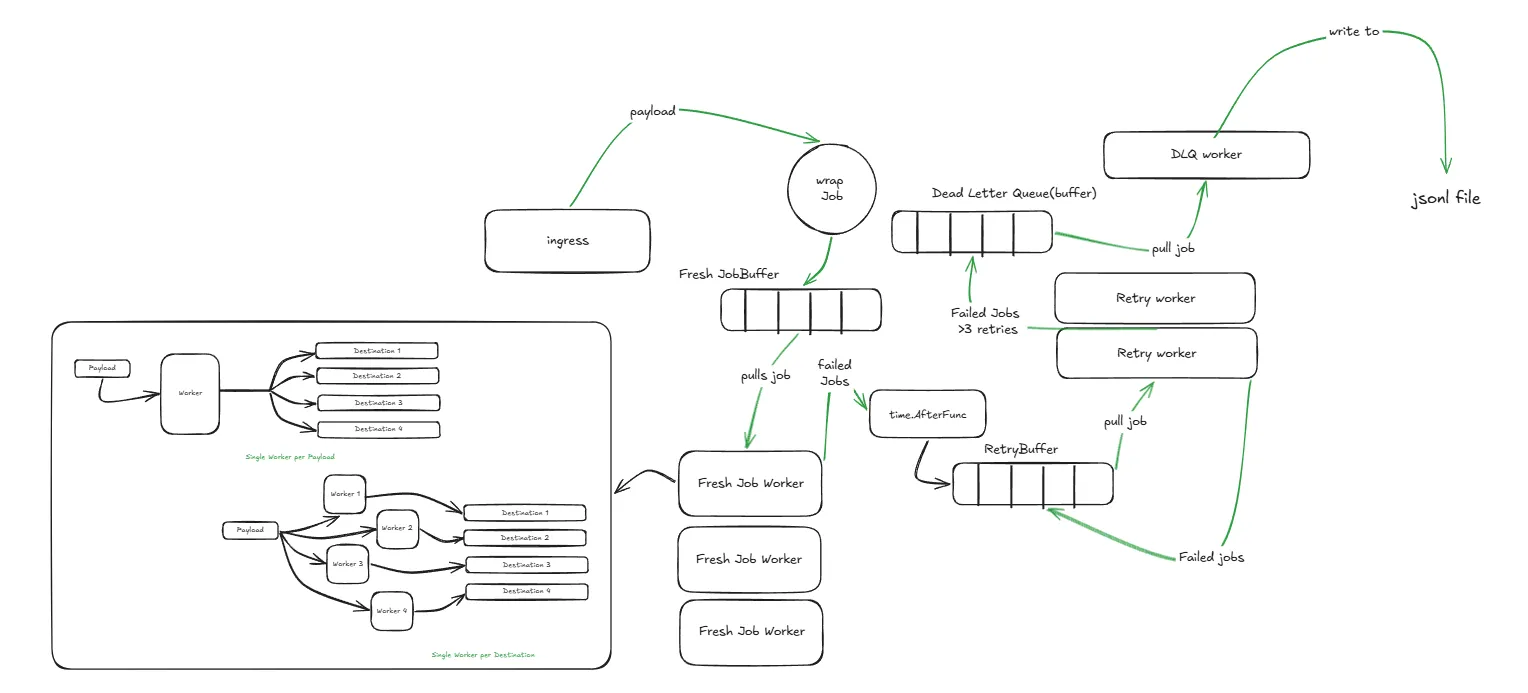
So I refactored the worker design itself. Instead of a worker being concerned with all endpoints, I assigned one worker for each endpoint. i.e., for one payload, I’d have ‘n’ workers where ‘n’ is the number of destination endpoints.
and I updated the Job struct to reflect that:
type Job struct {
EventID string `json:"event_id"`
Payload json.RawMessage `json:"payload"`
RetryCount int `json:"retry_count"`
Destination string `json:"destination"`
}Separation of Concerns
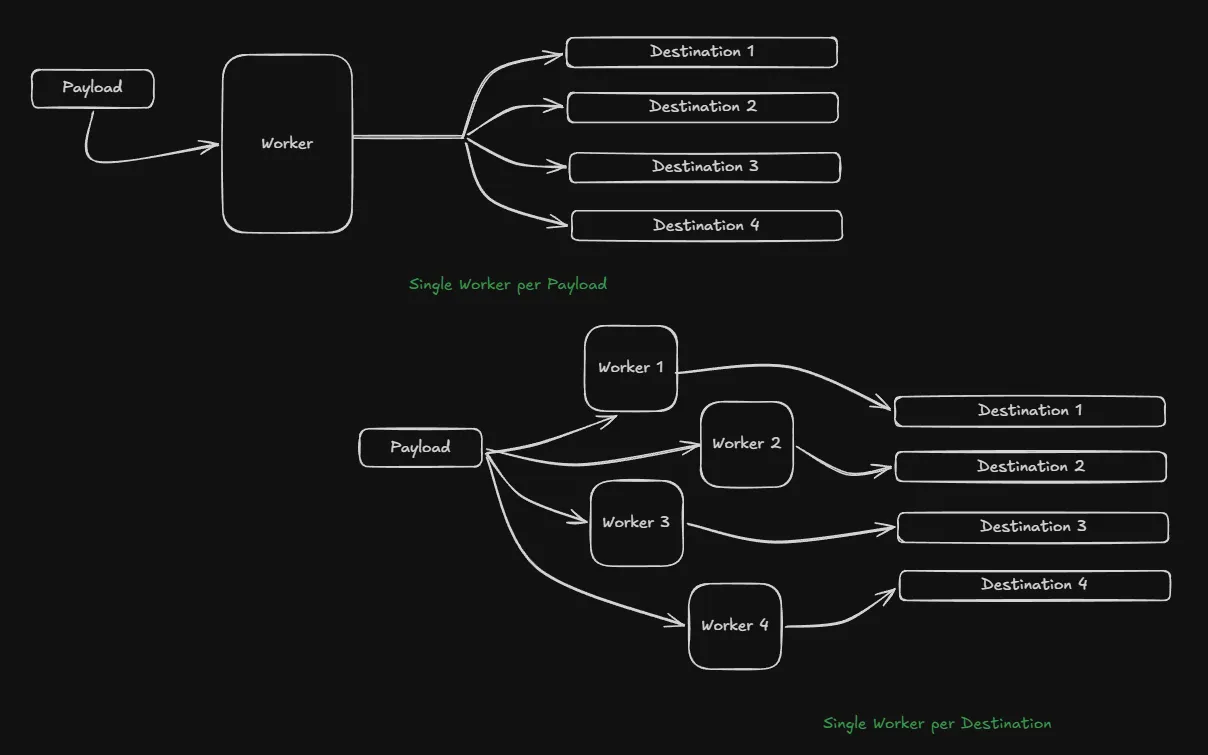
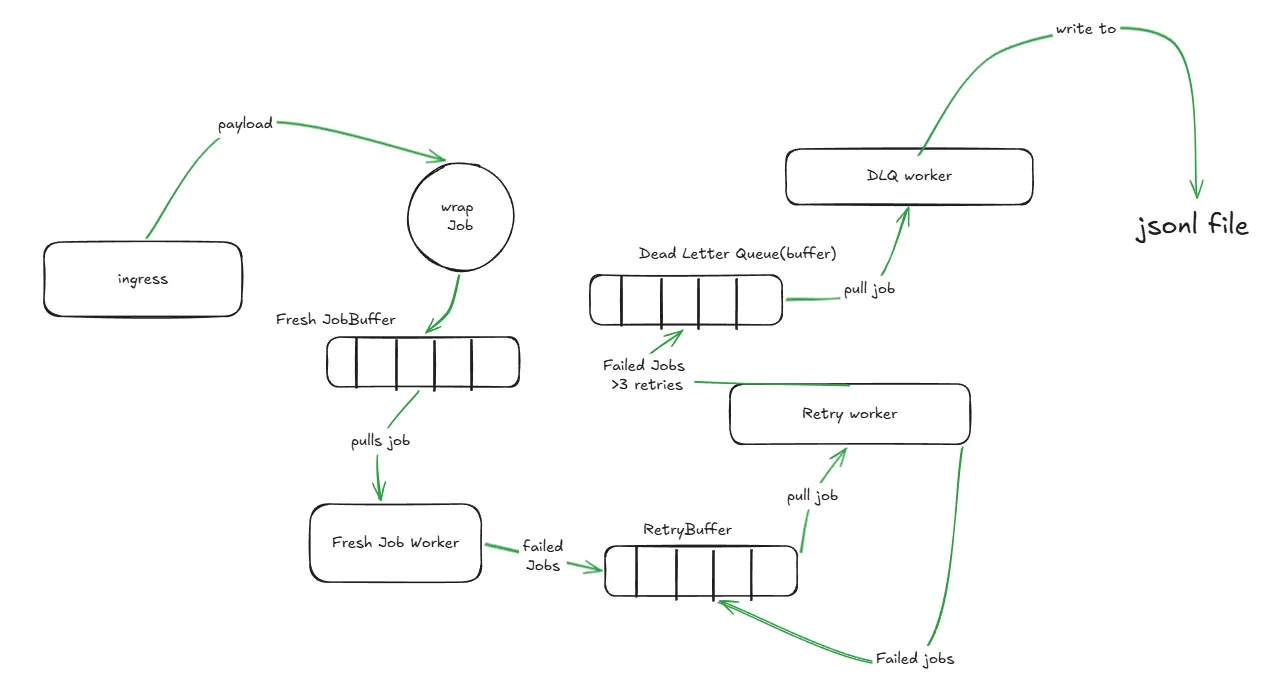
Now that the partial failure problem is solved with isolated workers, I needed to think about fresh incoming job and retries. When building a system prone to errors such as downstream server failures, the system must be willing to retry a failed job for a sensible number of times. Here I chose 3 (that’s kind of a standard value I guess).
Even though retries and fresh job processing is incredibly similar, they have two distinct concerns. The fresh jobs handle incoming Jobs as soon as they arrive while retries work on jobs that failed at least once. Hence, I have to separate these two mechanisms using a separate buffer and worker pool for both.
Now the system has:
Fresh Job Buffer + Fresh Job Worker Pool and a Retry Buffer + Retry Worker Pool.
Each buffer in the system is a simple go channel.
This also works in our advantage because now the retry jobs will go into their very own separate buffer and will not fill up the fresh job worker thereby hindering any actual fresh jobs from being queued.
Throttling & Jitter: How Not to DDoS Your Clients
Now that we’ve refactored our workers and added a DLQ, our system will be considerably fast. But then comes another problem: If the requests to downstream server fail then our worker pool is going to constantly pick all of those failed jobs from the queue and instantly retry them.
This is what system engineers call a Thundering Herd problem. The millisecond that third-party server boots back up, our system (and every other system waiting on it) will instantly slam it with thousands of retries, immediately crashing it again.
To fix this, we need Exponential Backoff.
Instead of retrying instantly, the system makes the job wait. And every time it fails, it exponentially increase the wait time.
const BaseDelay = 1 * time.Second
multiplier := math.Pow(2, float64(count))
backoff := float64(BaseDelay) * multiplierThis is better, but it still has a fatal flaw. If a massive batch of webhooks fails at the exact same time, their exponential backoffs will be mathematically identical. They will wait the delay and then wake up at the exact same millisecond, and slam the server together.
To protect the downstream server, I had to desynchronize the retries. We can do this by introducing randomness, a concept popularized by AWS architecture known as Full Jitter.
Instead of waiting the exact backoff time, we calculate the max backoff, and then pick a random number between zero and that maximum.
const MaxDelay = 5 * time.Minute
// Cap the backoff to the maximum allowed delay
if backoff > float64(MaxDelay) {
backoff = float64(MaxDelay)
}
// apply full jitter
jitteredBackoff := backoff * rand.Float64()
return time.Duration(jitteredBackoff)Now, the retries are spread out like a gentle mist instead of a firehose.
The dead letter queue
Well, as the name suggests it’s a queue that stores dead letters and here letters refer to jobs that have failed more than 3 times and are now considered dead i.e. there is no point in trying anymore.
So a proper system does require a mode to track the jobs that have failed relentlessly and have been moved from the worker queue. Interestingly enough, I solved this by adding another buffer. So if a job fails more than 3 times we simply push it into the DLQ Buffer instead of the retry buffer.
Then again, a proper system tracks DLQs to make use of it. Simply collecting dead jobs in a buffer makes no sense. A DLQ is present so that the system can review what caused consistent failures and see if we can use the information to improve the system from our end or maybe change something and later retry the job.
If you look at a dead job in a queue and all you see is the payload, you have no idea why it failed. Was it a 400 Bad Request or a 504 Gateway Timeout? To fix this, I updated our Job struct to capture the exact string value of the final error right before it dies.
type Job struct {
EventID string `json:"event_id"`
Payload json.RawMessage `json:"payload"`
Destination string `json:"destination"`
RetryCount int `json:"retry_count"`
LastError string `json:"last_error,omitempty"`
}waford does not have any complicated DLQ analysis since implementing that right now would be a deviation from our actual core feature.
Now I need a persistent storage to keep the dead jobs. Now I’m not keen on spinning up a DB just for this so the next best choice is a JSON file. If you try to append to a standard [{}, {}] JSON array file, you have to load the entire file into memory, append the item, and rewrite it. If your DLQ gets large, this will crash your server.
The solution I used here is JSON Lines (.jsonl). Every line is a complete JSON object separated by a newline (\n). This allows us to open the file in APPEND mode and write directly to the disk with almost zero memory footprint.
Thread-Safe Disk I/O
I have 100+ concurrent background workers processing retries. If they all try to open and append to dlq.jsonl at the exact same millisecond, I’ll get an assortment of file lock errors and corrupted text.
Instead of adding complex mutex locks, we can rely on Go’s CSP (Communicating Sequential Processes) architecture. I created a DLQBuffer channel and spin up exactly one dedicated DLQ worker. The 100 retry workers simply toss dead jobs into the channel, and our single DLQ worker safely reads from the channel and writes to the disk one by one.
At this point the whole setup looks something like this
Taming Rogue Requests with Context
At this point, we have workers, retries, jitter, and a DLQ. The system feels solid. But there’s a massive vulnerability: What if a destination server doesn’t reject our request, but just holds the connection open forever?
Why is that a problem you ask? If a destination server holds this connection it means the worker that is trying this operation never finishes. If all the workers get busy similarly, then the fresh job buffer gets chokes and new incoming jobs cannot enter the buffer. This will drastically affect latency.
In Go, the default HTTP client doesn’t have a strict timeout. If the destination server hangs, the worker goroutine hangs with it. If 100 workers get stuck waiting on a dead server, our entire webhook forwarder paralyzes.
Fortunately the fix is simple enough, instead of using http.NewRequest (which I was using in our sendRequest() function) we can now use http.NewRequestWithContext.
// Create a context that strictly expires after 5 seconds
reqCtx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
// Pass it to the request
err := sendRequest(reqCtx, current.EventID, current.Destination, current.Payload)
// Immediately free the timer resources
cancel()Now, if a server hangs, Go forcefully severs the TCP connection exactly at the 5-second mark, returns a context deadline exceeded error, and frees up the worker to try the next job.
Notice that I explicitly called cancel() immediately after the request finished, instead of using the standard defer cancel(). Because our worker runs in an infinite for loop, the surrounding function never returns. If I had used defer, the context timers would stack up in memory endlessly with every webhook, eventually causing a fatal memory leak.
Graceful shutdowns
Graceful shut downs are part and parcel of every good systems and this system needs one too. I have to protect the data when the system shuts down due to obvious reasons(👀).
We can do this in Go by using sync.WaitGroup to track active workers and signal.NotifyContext to listen for the OS interrupt.
appCtx, stopApp := signal.NotifyContext(context.Background(), os.Interrupt, syscall.SIGTERM)
defer stopApp()
//
//... rest of the server code (start workers, create server, start the server etc.)
//
// Block the main thread until the OS signal cancels the context
<-appCtx.Done()
slog.Info("[server] Shutdown signal received. Commencing graceful shutdown...")
// Shutdown the HTTP server so no new webhooks arrive
shutdownCtx, cancelHTTP := context.WithTimeout(context.Background(), 5*time.Second)
defer cancelHTTP()
srvr.Shutdown(shutdownCtx)
// Wait for the workers to finish their current requests
slog.Info("[server] Waiting for background workers to finish...")
app.WG.Wait()
slog.Info("[server] Graceful shutdown complete. Goodnight!")But there’s a subtle flaw that might go unnoticed here: The Panic Trap.
Remember how the retry system used exponential “Jitter” Backoffs to reschedule failed jobs? Well, that rescheduling needs to happen in the background or else it will keep the worker active on the same job, doing nothing, until the rescheduling is done which is really bad (quite obvious!). To solve this problem I used a time.AfterFunc to push jobs back into the RetryBuffer channel after a delay.
But if I triggered a shutdown and closed that channel, any sleeping timer that woke up a millisecond later would try to send a job to a closed channel. In Go, sending to a closed channel causes a fatal panic. Interesting isn’t it?
To fix this I refactored the workers to use select . Instead of closing channels, I passed the global shutdown context into every worker and replace the simple timer call with a lightweight goroutine running a select statement.
go func(j Job, d time.Duration) {
select {
case <-ctx.Done():
// The server is shutting down! Safely abort the sleep.
return
case <-time.After(d):
// Timer finished normally, safe to requeue.
s.JM.RetryBuffer <- j
}
}(current, delay)If the server shuts down, the ctx.Done() channel receives a signal instantly. The Go scheduler immediately unblocks the sleeping goroutine, bypasses the timer, and executes the return statement. The goroutine exits safely. Zero panics. Zero lost active connections.
By now our system is better and all the necessary components have been built. It’s time to test!
The chaos test
With the logic locked in, it was time to prove it worked. I wrote a separate “Chaos Server” to act as a hostile destination endpoint. I programmed it with a probability do one of three things:
- Return
200 OKinstantly. (simulate success) - Return
500 Internal Server Error. (simulate failure) - Sleep for 6 seconds and do nothing. (simulate slow downstream)
I pointed waford at the Chaos Server and fired a webhook.
The logs were awesome! The system perfectly absorbed the 500s, calculating jittered delays and retrying. When a worker hit the slow downstream, the 5-second reqCtx precisely severed the connection before the 6-second sleep finished. Failed jobs cleanly routed to the dlq.jsonl file.
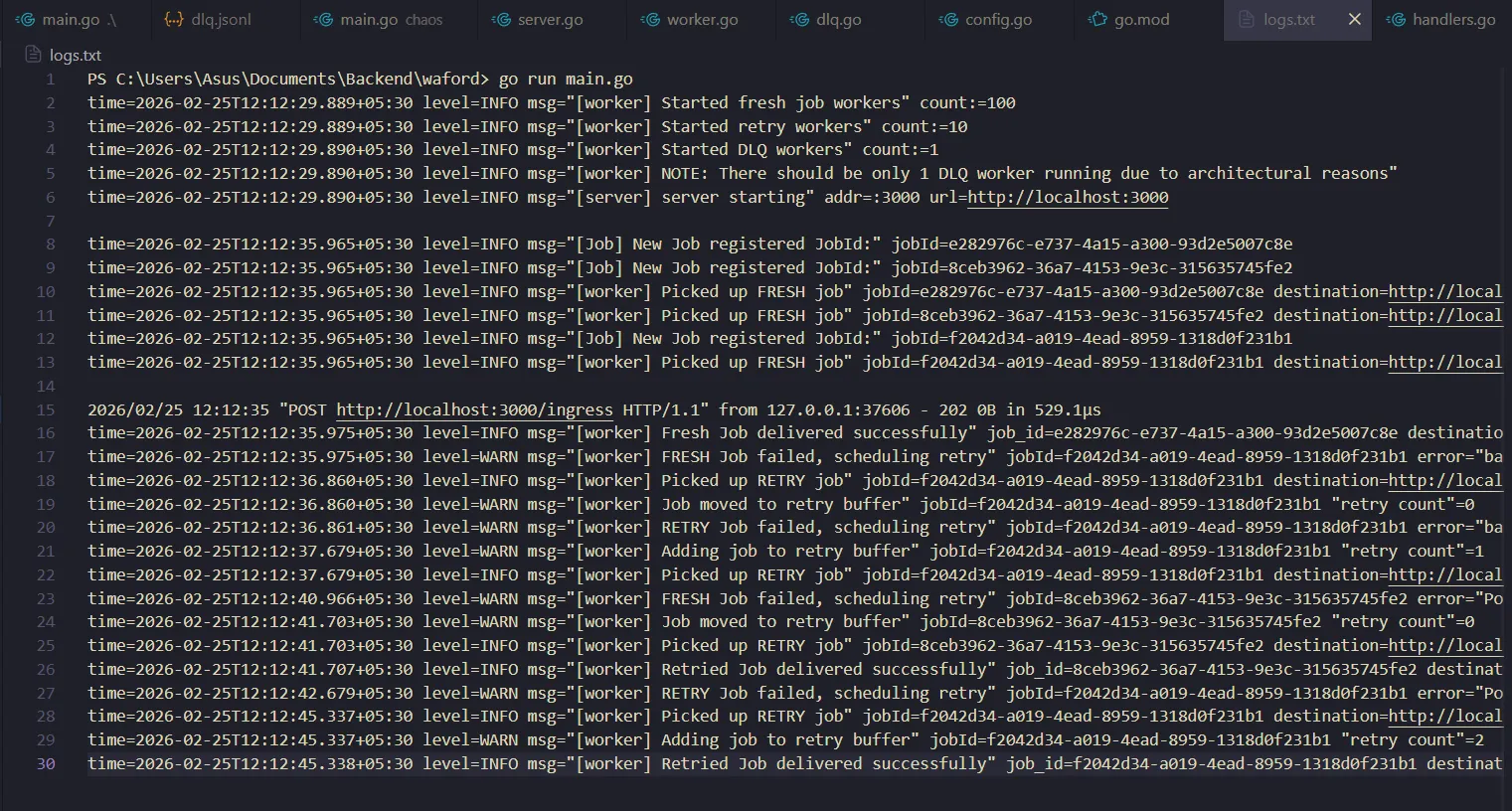
Now it was time to test for the physical limit: Load testing
The 5-Second Bottleneck
I used hey (a Go load testing CLI) to blast waford with 5,000 concurrent webhooks with 100 concurrent streams. Because my ingress fans out to 3 destinations, that meant injecting 15,000 jobs into the system instantly.
The results were uh… interesting. The summary numbers were negative and hence meant nothing (I assumed it was due to the huge amount of time it took to process) but the latency numbers were the most interesting.
p50 median showed exactly 5.00s. That meant half of the requests took exactly 5 seconds to finish. Why was my lightning-fast Go server suddenly making clients wait exactly 5 seconds for a simple 202 Accepted?
Diagnosis: Natural Backpressure
The JobBuffer channel was sized at 100. During the stress test, all 100 workers grabbed the first batch of jobs and slammed into the Chaos Server’s slow server. At a certain point, all the workers were stuck waiting 5 seconds for the context timeout and they couldn’t pull new jobs from the queue.
The channel filled up. When the 101st request hit the ingress endpoint, s.JM.JobBuffer <- newJob physically blocked the HTTP handler. Go literally froze the incoming request, waiting exactly 5 seconds for a worker to finish and free up a slot in the channel.
The system had protected its RAM from an Out-Of-Memory (OOM) crash, but it did so by holding the client’s connection hostage.
Load shedding
Holding connections open is dangerous. If the client sending the webhook has a 3-second timeout, they will sever the connection, assume we never got it, and aggressively retry, making our traffic jam exponentially worse.
We needed to trade “Availability” for “Reliability.”
If the queue is full, we shouldn’t make the client wait. We should instantly reject them so they can back off. This is called Load Shedding. It might sound like something complicated but it’s incredibly easy to implement.
The earlier handler accepted the payload, wrapped it in a Job struct and then pushed it into the channel. To support load shedding I used select statement with a default case in the handler.
select {
case s.JM.JobBuffer <- newJob:
// Success! The channel had room.
default:
// The channel is full. SHED THE LOAD!
http.Error(w, "server is at capacity", http.StatusTooManyRequests)
return
}Time to rerun the test!
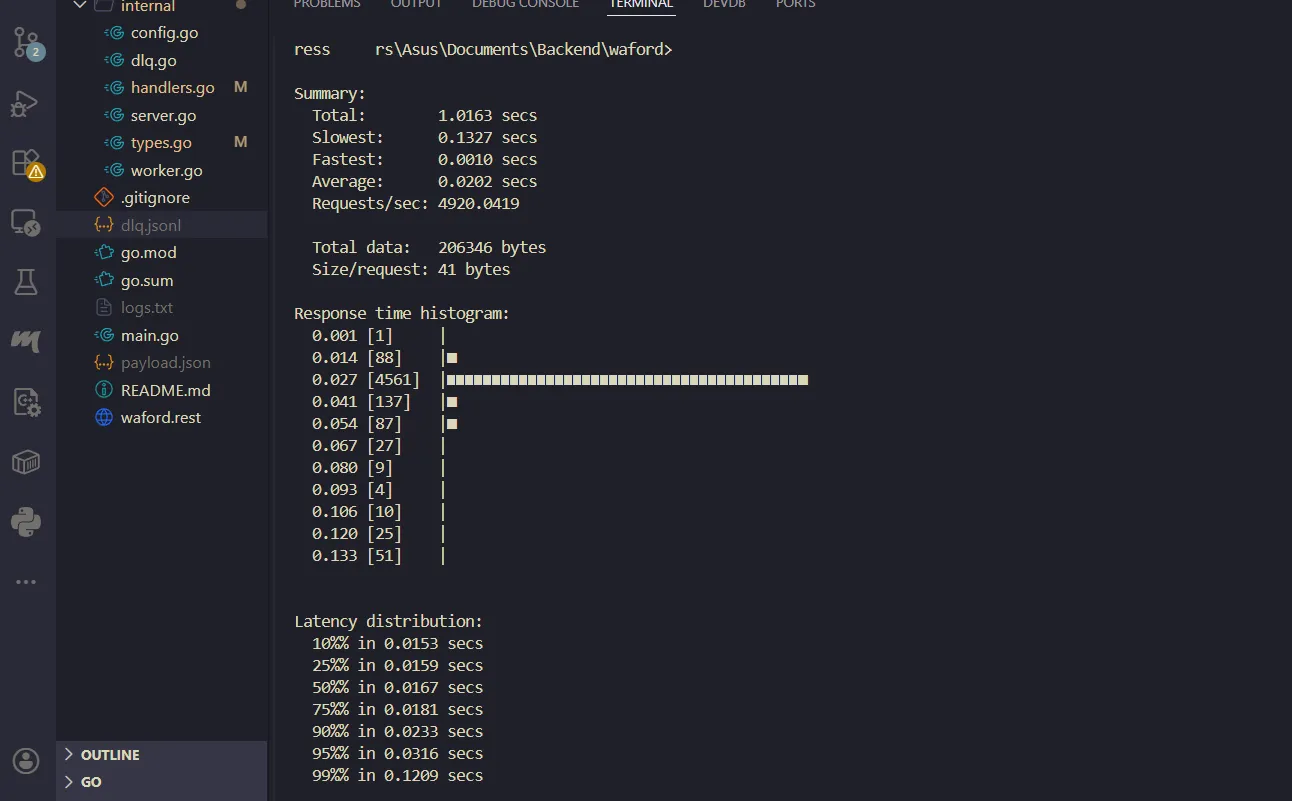
The test finished in 1.01 seconds. The average latency dropped to 0.02 seconds.
The system processed the exact maximum number of jobs it could physically handle through the background workers, and instantly deflected the rest with 429 Too Many Requests.
waford was no longer just a script. By leveraging isolated micro-jobs, jittered backoffs, context cancellations, and load shedding, it had evolved into a resilient, production-grade system capable of surviving whatever the internet threw at it.
The road ahead
While hey and our local Chaos Server helped us harden the core routing and backoff logic, an in-memory distributed system is never truly “finished.” These tests proved the concurrency model holds up under pressure, but moving forward, there are a few critical architectural limits one can test and improve:
- Surviving Hard Crashes (Durable Queues): Right now,
waforduses Go channels. If the server loses power or the process is violently killed (SIGKILL) bypassing our graceful shutdown, any jobs currently sitting in theJobBufferorRetryBufferare lost. To guarantee true “at-least-once” delivery, the next step would be implementing a Write-Ahead Log (WAL) or swapping the in-memory channels for an embedded persistent queue like SQLite or BoltDB. - Per-Destination Rate Limiting: Currently, our backpressure protects our server globally. But what if one destination (a massive database) can handle 1,000 RPS, but another (a Slack webhook) only allows 1 RPS? One could implement a Token Bucket algorithm per destination to dynamically throttle workers based on the downstream service’s specific API limits.
- Soak Testing & Observability: Blasting 5,000 requests in one second is great for finding race conditions, but even more important is testing long-running processes. One could use a different testing tool like
vegetato add a proper consistent load for a long time (24-48 hours) to see how the system behaves and take notes.
Building waford started as a “simple” one-shot exercise and turned into a deep dive into the realities of distributed systems. It was a brutal reminder that in backend engineering, the happy path is easy; it’s the failures that define your architecture.